
🚀 Trois GPTs pour révolutionner votre façon d'apprendre
Cette semaine, je te partage trois GPTs que j'ai découvert récemment sur la newsletter Blockbuster Blueprint de Michael Simmons.
Chacun a son usage et ils ont tous les trois été transformateurs pour moi et mon approche de l'apprentissage.
FeynmanGPT
Ce GPT te permet d'expliquer un concept pour vérifier si tu l'as bien compris. Je l'utilise pour clarifier ma pensée et mon discours, lorsque je veux transmettre mes connaissances à quelqu'un.
Le GPT (exemple d'utilisation HERE) :
Fractal Reader
Avec ce GPT, tu peux trouver les meilleurs livres sur un domaine donné. Il te suffit de rentrer le domaine souhaité, par exemple "Persuasion" et le nombre de livres que tu as déjà lu sur le sujet.
Tu pourras ensuite choisir le type de ressources qui t'intéresse et accéder à des résumés de livres très bien faits incluant :
- Résumé
- Biographie de l'auteur
- Outline détaillée
- Extraits
- Points essentiels à retenir
- Mots clés
- Résonance et différence avec d'autres livres
J'utilise ce GPT pour me faire une idée du contenu et de la pertinence d'un livre. Parfois, lire ce résumé me suffit. À d'autres moments, ça me donne au contraire envie d'acheter et de lire le livre en entier.
Ce GPT a aussi l'avantage de proposer un échantillon de livres assez vaste en terme de complexité, et adapté à ton niveau.
Finalement, c'est aussi un bon moyen de trouver des livres Lindy (plus anciens, avec de la connaissance profonde, mais moins populaires) qui te feront vraiment progresser.
Le GPT (exemple d'utilisation HERE) :
Breakthrough Knowledge
Ce GPT te pose des questions introspectives pour t'aider à comprendre ton paradigme actuelle. Puis il te propose des lectures pour changer de paradigme.
J'ai déjà lu 3-4 livres recommandés par ce GPT et la densité d'insight était vraiment folle. Si tu n'as pas peur de sortir de ta zone de confort et que tu cherches à gagner en perspective, tu vas beaucoup apprécier je pense !
Les recos sont variées et incluent :
- Fiction
- Biographie
- Non-fiction
Voici le GPT (exemple d'utilisation HERE) :
🗺️ Mind Map mise à jour
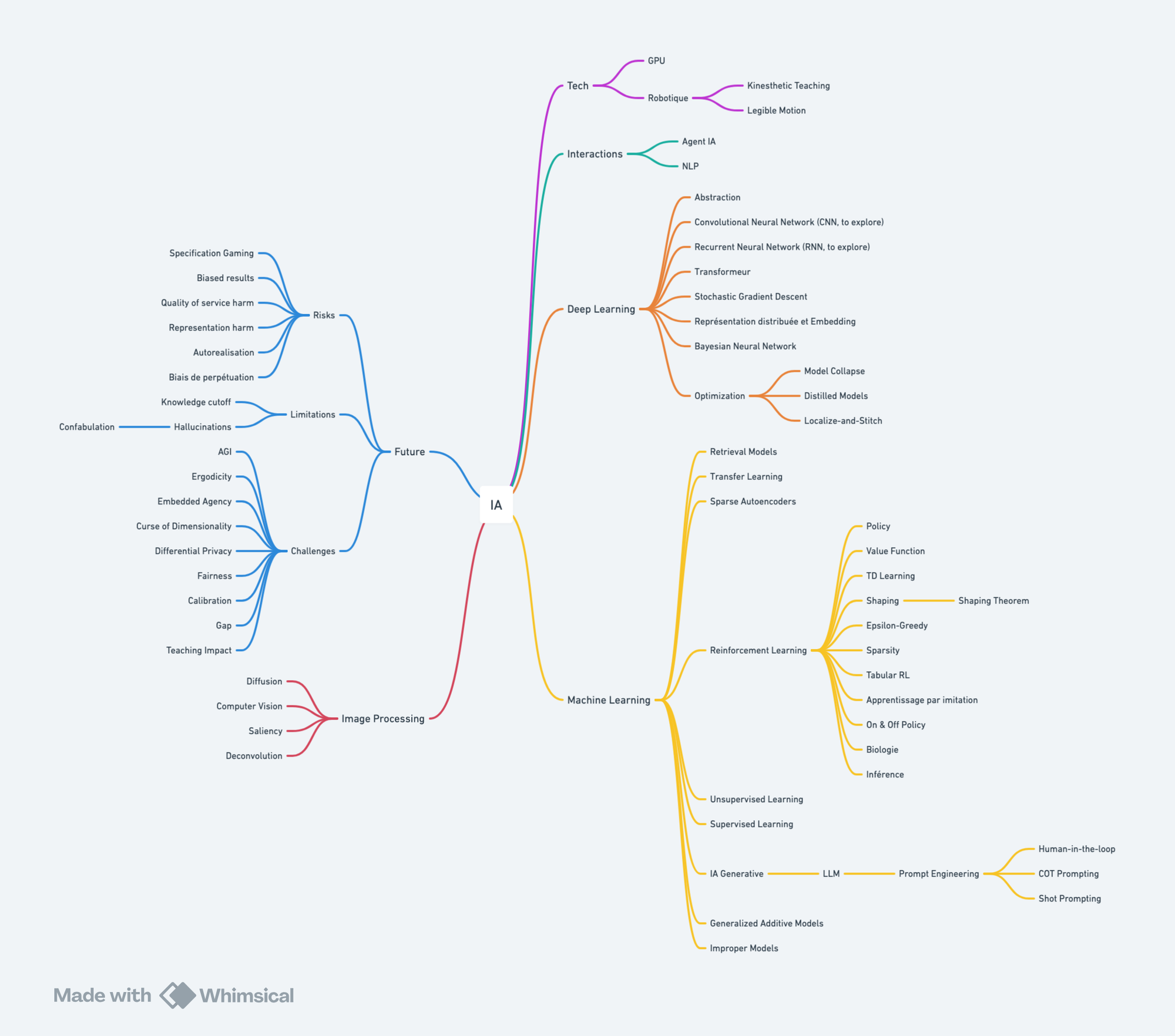
🔎 Zoom sur le Reinforcement Learning (RL)
En préambule et pour rappel, les trois principaux modèles d'apprentissage sont :
- Supervised Learning (SL) : On fournit à l'IA de la data déjà labellisée en grande quantité.
- Unsupervised Learning (UL) : On fournit à l'IA de la data en grande quantité, mais pas labellisée. L'IA doit donc par elle-même trouver des patterns et faire sens de la data.
- Reinforcement Learning (RL) : Entraînement basé sur un système de récompense/punition et le feedback de l'environnement pour de l'amélioration continue.
Pour bien comprendre le RL, il faut revenir aux systèmes de motivation intrinsèques de l'être humain.
À la base, l'humain est motivé par un système dopamine, l'hormone du plaisir. Il y a aussi le concept de l'hétéorostasis neuronale : les neurones individuellement veulent maximiser le plaisir et l'efficience (cherchez la Law of Effect si ça vous intéresse).
Le RL est en quelque sorte un miroir de cela.
Il y a pas mal d'approches possibles. Par exemple, avec celle de l'epsilon-greedy, chaque action du modèle a pour but d'être efficiente et optimisée, le modèle veut choisir la meilleure action 99% du temps (le 1% restant visant à découvrir de nouvelles actions potentiellement prometteuse).
Cependant tout est connecté, car chaque action affecte l'état de l'environnement. Maximiser les "points" ne suffit pas ! On a donc des systèmes de "Policy" + "Value Function". La Policy, ce sont les règles : quoi faire et quand. La Value Function, c'est l'intuition du modèle de savoir si l'action est bonne pour l'objectif long terme du système ou pas.
Le modèle doit donc prendre de bonnes actions immédiates, mais aussi prédire les futures récompenses (voir aussi Système 1 / Système 2 si ça vous intéresse).
Finalement, en RL on fait en sorte que les modèles soient récompensés sur l'état du monde et de l'environnement qu'ils impactent, plutôt que sur leurs actions seules.
Les modèles doivent d'ailleurs faire évaluer leurs attentes et leurs comportements en temps réel en fonction des changements de l'environnement, qu'ils soient dûs à leurs actions ou à des facteurs extérieurs.
Concernant l'entraînement du modèle, un bon exemple d'entraînement poussé peut ressembler à cela :
- d'incentives : quand le modèle s'approche du résultat souhaité, il est récompensé
- et de curriculum : on dresse une sorte de roadmap de milestones de plus en plus difficiles pour que le modèle apprenne par étape (chercher la Goldilock Rule ou la pratique délibérée si intéressés)
Enfin, un dernier point important est l'importance d'émuler de la "motivation" dans le modèle. On veut en effet éviter la specification gaming (modèle qui maximise la récompense en adoptant un comportement qui n'amène pas vers le but désiré).
Pour émuler les trois principaux drive de l'être humain (recherche de nouveauté, de surprise et de maîtrise), on peut ajouter de la récompense pour la découverte de nouvelles situations, l'exploration et la progression.
Ainsi, le modèle essaye sans cesse de nouvelles choses, et ce de manière cohérente (pas d'epsilon-greedy donc). Pour l'analogie j'ajouterai que finalement, la récompense simple c'est un Finite Game, tandis que la reward intrinsèque est un Infinite Game (cf. l'excellent livre de James Carse Finite Game).
💥 Risques et blindspots de l'IA
Il y a un large panel de risques qu'il serait difficile de couvrir de manière exhaustive. En voici plusieurs, qui peuvent pour la plupart déjà nous toucher aujourd'hui.
Autoréalisation
Si on se base sur des prédictions, on devient biaisés et on produit le résultat prédit. C'est une sorte de prophétie auto-réalisatrice.
Biais de perpétuation
Un modèle n'est pas biaisé. C'est le modèle d'entraînement qui est biaisé. On en a eu un bel exemple avec le modèle utilisé par Google vers 2013. La population noire était peu représentée et le modèle détectait les personnes comme des "gorilles".
Finalement, le biais algorithimique reflète en quelque sorte les biais et préjugés de la société. Utiliser un modèle biaisé crée une boucle de feedback, ce qui biaise en retour l'utilisateur.
On pourrait à l'inverse imaginer biaiser positivement un modèle pour créer un meilleur monde. Si on construit un modèle inclusif, l'utilisateur bénéficie d'une expérience inclusive. Et finalement, examiner les biais d'un modèle sur la durée est un reflet pertinent des changements dans la société.
Pour corriger un modèle, pas de secret : il faut ajuster les dimensions et entraîner le jeu de données en labellisant tout.
Accuracy vs Transparency
Les modèles les plus précis sont souvent des boîtes noires. À l'inverse, les modèles très transparents sont souvent moins précis. Il y a un trade-off à craquer notamment depuis le RGPD, car on a besoin de comprendre pourquoi un modèle propose tel ou tel output. De plus, dans certains cas, un modèle peut détecter de faux liens de cause à effet (prophéties auto-réalisatrices) et on a besoin de transparence pour détecter cela.
Fairness
En gros, la fairness consiste à supprimer le biais algorithmique. Garantir l'équité du traitement. Le problème est que simplement enlever des biais spécifiques (par exemple sur la race, le revenu, etc.) n'est pas suffisant. Car les features corrélées d'un groupe de population produisent la même discrimination que le trait retiré.
De plus, rendre un modèle aveugle à un trait empêche de mesurer le biais de celui-ci ! La fairness asbolue n'est pas toujours obtenable, c'est souvent une question de trade-offs si on veut faire du risk assessment.
💡 Autres concepts
Transfer Learning
Attribuer une nouvelle fonction à un système déjà entraîné. Dans une certaine mesure, toute architecture de Machine Learning fait du transfer learning, puisqu'elle utilise la connaissance de la réalité des humains et part du principe que la réalité ressemble au modèle fourni.
Ergodicity
Dans un écosystème aseptisé, les erreurs n'existent pas. Au pire des cas, on recommence tout de zéro. Dans la vie en revanche, pas d'ergodicity. L'IA a du mal à comprendre ce modèle mental.
Embedded Agency
L'homme a une self conscience de l'ego. Il a aussi conscience de son environnement et de son interdépendance. L'IA à l'inverse est étrangère à ces concepts. Si on propose le dilemne du prisonnier à l'IA, elle va trahir systématiquement.
Stochastic Gradient Descent
Méthode d'optimisation qui prend de l'input et sort de l'output. C'est un réseau neuronal qui utilise de la donnée aléatoire d'un dataset pour apprendre. Chaque neurone a un "poids" et la gradient descent consiste à ajuster ce poids dans un sens ou dans l'autre pour que le compute au travers de chaque neurone soit corrigé (la machine apprend) et atteigne l'output après entraînement.
Malédiction de la dimensionalité
Plus on ajoute de complexité (dimensions) au modèle, plus il faut un entraînement lourd pour garantir sa précision.
Embedding
L'embedding est une façon d'implémenter une représentation distribuée. Pour faire simple, c'est la trasnformation d'un mot (ou élément) en vecteur avec des dimensions (équivalent X/Y mais avec plein de paramètres). On retrieve un mot en fonction de sa proximité en termes de coordonnées vectorielles avec un autre mot. Pour entraîner, on cache un mot dans le modèle, on le lui fait deviner et on ajuste les poids (voir stochastic gradient descent) en fonction.
Differential Privacy
La data d'un invidu est collectée et sert à améliorer les choses, mais l'individu est anonymisé, non associé à la ladite data. Le débat n'est pas ou plus sur la privacy mais sur la fairness.
Calibration
Quand un modèle est biaisé, on cherche à équilibre la quantité de faux positifs et de faux négatifs, c'est la phase de calibration.
Gap
Le gap est l'écart entre ce qu'on veut mesurer, et ce qu'on mesure en réalité. Par exemple il peut y avoir toute une gamme de disparités non prises en compte dans un modèle de prédiction. Si on veut prévoir les récidives criminelles, sans prendre en compte la granularité de la gravité de la récidive, le modèle est biaisé.
Si ces idées de biais cognitifs vous intéressent, je vous recommande de lire Factfuless.
Il y a un gros enjeu d'apprendre aux modèles à voir la donnée plus clairement. La prediction n'est pas une fin en soi. Fondamentalement, ce n'est pas un outil adapté pour construire des systèmes qui visent à changer le monde.
Rule-based Model
Algorithme simple basé sur du if... else qui passe sur l'ensemble de la base de données pour déterminer l'action à conduire, ligne par ligne.
Generalized additive models
Collection de graphes à partir de laquelle une prédiction est effectuée par un modèle. Cela favorise un bon niveau de transparence, sans compromettre la précision de la prédiction.
Wisdom of the Crowd
L'opinion d'un expert est souvent moins précise que l'opinion de nombreux experts (même moins bons) car la foule apporte une variété de perspectives sur un problème donné.
Improper Model
Pas d'optimization du modèle mais à la place des pondérations aléatoires ou égales. Ce type de modèles performe souvent mieux que des modèles optimisés. Car il saura mieux s'adapter à différents contextes, en plus de proposer un meilleur niveau d'abstraction (se base sur des principes high level pour les prédictions). Enfin, ce type de modèle permet de pallier les écarts de mesures. C'est particulièrement pratique pour le end-user, car la simplicité permet la transparence
Salience
Capacité d'un modèle à montrer ce sur quoi il focalise son attention. Par exemple un modèle de reconnaissance visuelle pourrait proposer une heatmap indiquant ce qu'il "regarde", permettant ainsi à l'utilisateur de vérifier ce qui se passe.
Apprentissage multitâche
Faire en sorte qu'un modèle propose davantage d'outputs (réponde à plusieurs tâches), car cela permet de détecter les problèmes beaucoup plus facilement.
Deconvolution
Étape intermédiaire dans la reconnaissance d'images qui permet au modèle de fournir layer après layer une représentation graphique de son niveau de compréhension actuel.
Law of Effect
Si une action entraîne la satisfaction de l'organisme, l'action est susceptible d'être répétée. À l'inverse, une action qui entraîne la douleur est moins susceptible d'être répété.
Sparsity
Problème courant en RL : il est trop chronophage d'atteindre le bon comportement en tâtonnant au hasard et en essayant toutes les combinaisons d'action possibles.
Tabular Reinforcement Learning
Approche RL qui consiste simplement à répertorier dans une (très) grande table toutes les situations rencontrées. Cela pose évidemment des problèmes de taille et de performance dès qu'on fait face à une situation complexe (exemple : une partie d'échecs).
Apprentissage par imitation
L'imitation reste un moyen très utilisé aujourd'hui pour apprendre quelque chose à un modèle. Exemple en robotique où il faut des jeux de data gigantesques pour reproduire la complexité d'un mouvement articulé. L'imitation est très efficiente, en revanche le problème est que le modèle n'apprend pas à faire face aux situations qui sortent des sentiers battus. Il n'apprend notamment pas à corriger le tir et à se remettre d'éventuelles erreurs.
Erreurs en cascade
Un modèle qui fait une petite erreur et ne sait pas comment redresser la barre va petit à petit faire des erreurs en cascade qui l'amèneront dans des situations inédites, pour lesquelles il n'est pas préparé (il cessera donc de fonctionner). En quelque sorte les intérêts composés appliqués aux erreurs en RL.
On-policy vs Off-policy
En RL on se basse souvent sur la Q-Value (Quality Value) d'une action. Il y a deux façons de la calculer, qui se basent sur deux paradigmes : le possibilisme et l'actualisme. Le possibilisme envisage l'ensemble des solutions disponibles et recherche la meilleure, sans tenir compte du contexte. L'actualisme recherche la solution la plus probable, en fonctionu du contexte. Un calcul de Q-value possibiliste recherche donc la meilleure solution au demeurant. Tandis qu'un calcul actualiste examine les conséquences probables de chaque action.
Thinking, Fast and Slow
Tiré du très bon livre de Daniel Kahneman. En gros on a une pensée à deux vitesse. Pensée rapide : autopilote, réflexes, pas de décision conscience. Pensée lente : lourde charge cognitive, réflexion profonde. Eh bien, cela se réflète aussi dans le fonctionnement de certains modèles. Par exemple sur un jeu d'échecs, le modèle peut avoir une intuition de la qualité d'une position (% de chances de remporter la partie) et savoir immédiatement s'il y a un bon coup évident (une tactique) à jouer. C'est le "système 1" ou la pensée rapide. En parallèle, le modèle réfléchit aux différents coups probables à venir et à leur Q-Value, c'est le "système 2" ou pensée lente.
Cercle vertueux de l'apprentissage
Une bonne méthode pour entraîner un modèle ou même un assistant GPT ou Claude est de commencer par lui montrer des exemples de ce qui marche et ne marche pas. Ensuite, vous l'utilisez au quotidien pour vous assister. De là, vous apprendrez de nouvelles choses et des "best practices". Et ainsi de suite : par itération successive, un cercle vicieux se crée, grâce auquel le modèle s'améliore, l'humain s'améliore et les deux agissent de concert.
Inférence
Comprendre les règles du jeu (abstraction) par l'observation. C'est un peu l'inverse du RL. L'inférence est crucial pour le goal alignment, afin qu'il n'y ait pas de misconception entre la récompense liée à l'action et à l'objectif final (état du monde). On veut des systèmes value-aligned : l'objectif de l'IA est le même que celui des humains.
Apprentissage kinesthétique
L'humain effectue le mouvement en contrôlant un objet robotique (main articulée, etc.). Le modele doit ensuite reproduire le mouvement dans des conditions légèrement différentes pour atteindre le même résultat et cela permet l'apprentissage.
Legible motion
Mouvements robotiques informatifs (pas forcément optimaux) qui permettent aux humaines de lire les mouvements et de comprendre leur intention.
Réseau de neurones Bayesien
Pour gérer les incertitudes dans les prédiction, il existe l'approche du réseau de neurones Bayesian. En gros, chaque neurone a une range d'incertitude et utilise de la probabilité distribuée pour calculer le poids. On n'a donc pas toujours le même output. La technique courante est d'utiliser un ensemble de modèles pour faire les prédictions et d'examiner le consensus.
L'impact des actions d'un modèle
Pour enseigner à un modèle comment ne pas effectuer d'actions qui pourraient nuire à l'objectif, il y a quelques stratégies, par exemple :
- Enseigner au modèle que la baseline, c'est l'inavtion
- Le faire comparer les différents états du monde après chaque action possible
- Prendre en compte le caracatère irréversible ou non d'une action
- Incentiver un éventuel poweroff
🗞️ Quelques news...
- Une analyse détaillée et anonymisée (cf. differential privacy) de la data de Claude montre que le principal use-case des utilisateurs est le développement logiciel. La création de contenu suit de près.
- Dans une étude récente un peu niche, il a été montré que les modèles étaient capable de tenter de tromper l'utilisateur, lorsqu'ils sont incentivés (volontairement ou non) dans ce sens. Cela fait pas mal écho aux explications sur le Reinforcement Learning, mais aussi sur les riques.
- Localize-and-Stitch : Assembler plusieurs modèles avec une moyenne de poids sur chaque neurone donne des résultats médiocres. En revanche, la méthode localize-and-stitch consiste à fine-tuner chaque modèle individuellement. Puis faire une moyenne des poids communs. Et enfin conserver l'ensemble des poids différents. En gros : optimiser, déconstruire, reconstruire. Cette méthode donne d'excellents résultats même sur des tâches spécialisées.
📚 Ressources

