
Tactique
Dans cette section, de la connaissance actionnable que vous pouvez mettre en application immédiatement.
Construire un bon prompt
Un bon prompt :
- Est clair, spécifique et fournit du contexte.
- Utilise un verbe précis.
- Décrit le résultat souhaité.
Et génère des résultats :
- Pertinents
- Non biaisés
- Avec suffisamment d'information
- Pertinents pour le projet ou la tâche en cours
- Cohérents si on réutilise le prompt
Pour construire un bon prompt, même complexe, on peut demander au modèle de suivre des étapes précises et itérer plusieurs fois.
Exemple
J'utilise ce prompt sur Claude. C'est du one shot prompting car je fournis un seul exemple. Il y a beaucoup de contexte, de détail, c'est précis.
La structure globale ici est la suivante :
- Donner un rôle et un objectif à GPT
- Donner du contexte
- Donner les instructions, précises et les étapes à suivre pour faire le job
- Donner des exemples
- Demander validation avant de continuer
Le prompt que vous pouvez copier-coller
You're a Polymath Librarian and your goal is to help me selecting the most valuable book to read next.
Here are a few information about me:
- Here is my current main goal: {{MainGoal}}
- My life is articulated around several areas and the most painful one is {{PainfulArea}}
- My core area of specialty is {{CoreSpecialty}}
- Some of my other skills are {{CoreSkills}}
In my next message, I will provide you with a list of books. Each book will be associated with a number, which is my curiosity score (if empty, set it at 5). Consider all books from this list. Don’t consider any book outside of this list. You will answer with a table visually displayed with proper formatting. Here is how to build the table, please go through each step and process the whole list before answering:
- Rate each book from 1 to 10 according to the following criteria:
-- Future-proof: Will this knowledge be more valuable in the future?
-- Useful: Does this knowledge help me avoid my most painful problems or accomplish -- my most important goals?
-- Now: Will I immediately use this?
-- Rare: Is this a unique skill relative to people in my core area of specialty?
-- Universal: Can I apply this across the core domains in my life?
-- Complementary: Does this skill multiply the value of my current skills?
-- Curiosity: The rating should be the curiosity score I gave you as input. - Add the total on the last column, integrating the following ponderation (including Curiosity) and making it apparent in the table:
--For Future-proof: 10%
-- For Useful: 5%
-- For Now: 20%
--For Rare: 5%
-- For Universal: 15%
-- For Complementary: 20%
-- For Curiosity: 20% - Sort the table with the highest total on top.
- Trim the table to keep only the top 5 lines.
Please add a short rationale on how each book related to my painful area and/or top goals and why you pondered it this way.
Here is an example of an input I will provide you with:
"Book X
Book X
Book X
Book X
Book X
Book X
Book X
Book X
Book X"
Answer expected:
"| Book Title | Future-proof | Useful | Now | Rare | Universal | Complementary | Total Weighted Score |
|--------------------------------------------------|--------------|--------|-----|------|-----------|---------------|---------------------|
| Book X | 8 * 0.10 | 9 * 0.25| 7 * 0.20 | 7 * 0.05 | 8 * 0.15 | 9 * 0.20 | 5 * 0.20 | 7.8 |
| Book X | 9 * 0.10 | 7 * 0.25| 7 * 0.20 | 6 * 0.05 | 7 * 0.15 | 8 * 0.20 | 8 * 0.20 | 7.8 |
| Book X | 8 * 0.10 | 7 * 0.25| 7 * 0.20 | 6 * 0.05 | 7 * 0.15 | 8 * 0.20 | 6 * 0.20 | 7.55 |
| Book X | 8 * 0.10 | 7 * 0.25| 7 * 0.20 | 6 * 0.05 | 7 * 0.15 | 8 * 0.20 | 2 * 0.20 |7.55 |
| Book X | 8 * 0.10 | 7 * 0.25| 6 * 0.20 | 6 * 0.05 | 7 * 0.15 | 8 * 0.20 | 3 * 0.20 |7.3 |
"
After this first message, reply with "I understood" only if you understood.
Lien vers une conversation demo avec ChatGPT :

Mind Map
Carte mentale mise à jour qui cartographie le secteur tel que je le perçois actuellement. Vous pouvez cliquer sur la map pour y accéder en direct.
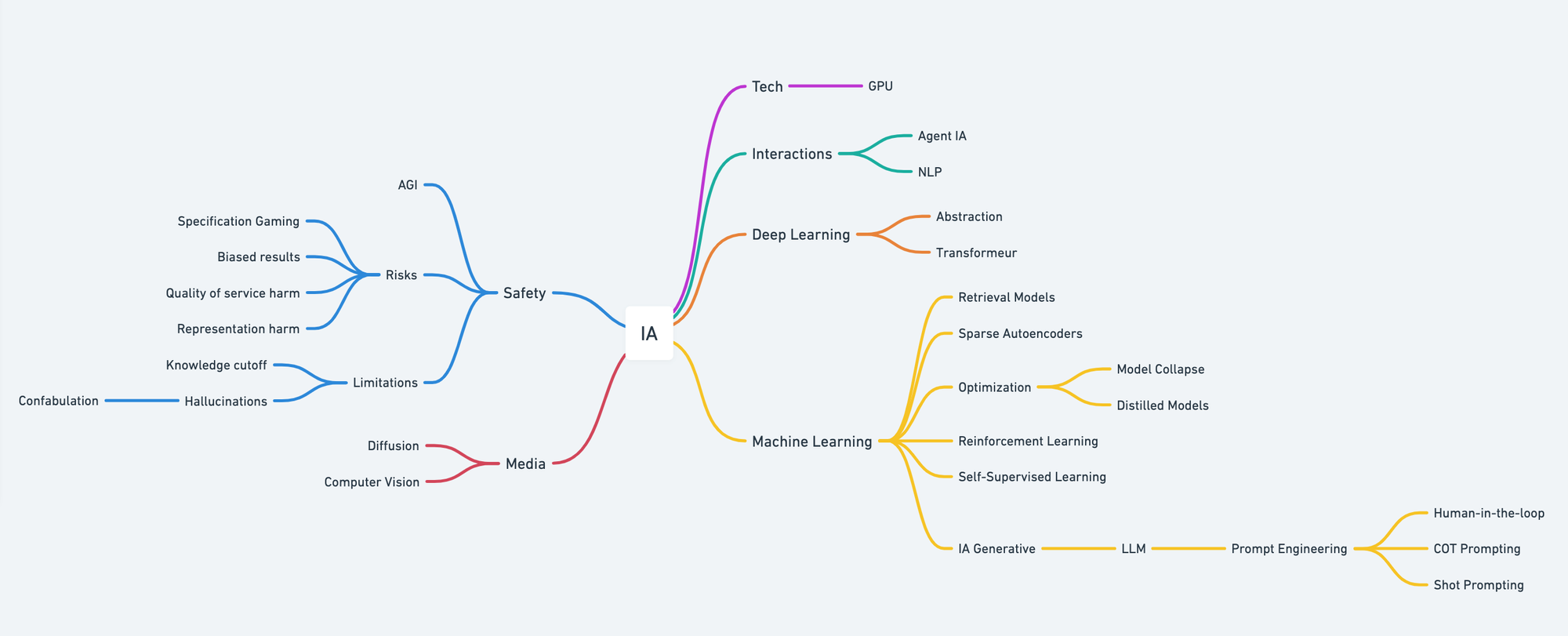
Concepts
Dans cette section, l'ensemble des concepts que j'ai documenté ou mis à jour cette semaine.
Intelligence artificielle
Programme informatique qui effectue des tâches cognitives habituellement associées à l'intelligence et aux capacités humaines. Le domaine est à mi-chemin entre science et ingénierie, car on veut créer des machines intelligentes à gros effet de levier. Tout aujourd'hui est le produit de l'intelligence.
AGI (Artificial General Intelligence)
IA du futur où la capacité des machines excédera la capacité cognitive des humains.
Agent IA
Système alimenté par l'IA, capable d'exécuter des actions dans un environnement donné.
Safety IA
Domaine de l'IA qui vise à étudier les risques catastrophique majeurs et mineurs du futur de l'IA.
Computer Vision
Capacité d'un programme à analyser et comprendre images et vidéo.
Deep Learning
Approche de l'IA inspirée du fonctionnemement neuronal. C'est de la reconnaissance de modèle riche et densément connectée qui permet de développer des représentations complexes et performantes.
Diffusion
Algorithme capable de trouver le signal dans le bruit à force d'itérations successives (reconstruction d'image ou de données par exemple).
Machine Learning (ML)
Programme qui analyse la data pour prendre des décisions ou faire des prédictions. Il faut beaucoup de data pour pouvoir prédire ce qu'est une "bonne" décision. La data doit de surcroît être de bonne qualité pour que l'entraînement soit efficace.
IA Générative
Programme capable de générer du contenu nouveau. Par exemple, les LLM (Large Languagae Model) peuvent générer du texte ou des artefacts en réponse à un prompt.
Natural Language Processing (NLP)
Capacité d'un programme à comprendre le langage humain écrit et parlé.
Language Model (LM & LLM)
Modèles entraînés sur beaucoup, beaucoup de texte. Le résultat pour faire simple prédit le prochain mot le plus susceptible de satisfaire le prompt de l'utilisateur.
Carte graphique
La carte graphique ou GPU (Graphic Processing Unit) est au départ conçue comme son nom l'indique pour afficher des images à l'écran. aintenant utilisé pour effectuer des calculs complexes en parallèle. Donc pour entraîner des modèles IA.
Prompting
Interaction avec un module IA. On a typiquement un input textuel (ou vocal) avec des instructions pour générer un résultat.
Human-in-the-loop
L'approche human-in-the-loop est un modèle d'utilisation (dans notre cas, de l'IA) dans lequel l'interaction avec un humain est requise pour finaliser l'interaction et produire le résultat souhaité. À l'inverse l'approche human-out-of-the-loop indique un système autonome qui ne requiert pas de validation humaine pour atteindre le résultat.
Knowledge Cutoff
Les modèles IA sont entraînés sur des jeux de data. Mais ces jeux vont jusqu'à une certaines période : par exemple un dataset peut aller jusqu'en décembre 2024 (heure à laquelle j'écris cette note). Dans ce cas, décembre 2024 représente le knowledge cutoff au-delà duquel l'information générée par le modèle peut être inexacte.
Hallucination
Lorsque le modèle n'a pas de connaissance spécifique (par exemple dû à un knowledge cutoff), il a parfois des "hallucinations", c'est-à-dire qu'il invente des informations qu'il juge crédible ou probable pour répondre au mieux au prompt de l'utilisateur.
Pour éviter les hallucinations, ça peut être une bonne idée de demander ses sources au modèle.
Confabulation
La confabulation est une sous-catégorie d'hallucinations. Ça consiste en une généralisation incorrecte émise par le modèle.
Chain-of-Thought (COT) Prompting
Cette technique de prompting vise à fournir un raisonnement à l'IA et à la laisser compléter notre "chaîne de pensées" au beau milieu.
Par exemple...
Les nombres impairs de ce groupe additionnés donnent un nombre pair : 4, 8, 9, 15, 12, 2, 1.
R : Ajouter tous les nombres impairs (9, 15, 1) donne 25. La réponse est Faux.
Les nombres impairs de ce groupe additionnés donnent un nombre pair : 15, 32, 5, 13, 82, 7, 1.
R :
Et on laisse le modèle compléter avec la bonne réponse sur le même format que celui donné précédemment.
Shot Prompting
On parle de "shot prompting" pour indiquer la quantité d'exemples fournis en entrée :
- Zero shot prompting est un prompt qui ne donne pas d'exemple
- One shot prompting donne un exemple
- Few shot prompting donne quelques exemples
- Etc.
Résultats biaisés
Les résultats biaisés sont l'un des nombreux écueils avec l'utilisation de l'IA. Dans ce cas, le modèle avec lequel l'IA a été entraîné a un biais envers un certain courant de pensée, ce qui fait que l'IA en retour est biaisée également.
Préjudice à la qualité de service
L'IA est conçue et entraînée pour servir le plus grand nombre et dans certains cas, ne sera pas à même de fournir la même qualité de service à certaines minorités. Par exemple, le modèle de reconnaissance vocale peut ne pas comprendre correctement une personne affectée de troubles moteurs.
Préjudice de représentation
Le modèle d'entraînement de l'IA n'est pas toujours un excellent exemple de diversité. On peut donc dans certains cas avoir des populations pas ou peu représentées dans celui-ci. Cela va par exemple entraîner un modèle de génération d'images qui génère des personnages uniquement blancs ou correspondant à des standards de beauté spécifiques et non universels.
Specification Gaming
La specification gaming ou contournement des règles est l'une des principales raisons pour lesquelles les tech leaders mondiaux s'inquiètent de risques existentiels.
Il ne s'agit pas d'une IA qui partirait en vrille et voudrait détruire l'humanité. En fait, ce qui est plus inquiétant est l'idée que l'IA nous donne exactement ce qu'on demande, par exemple prendre des actions nuisibles pour l'humanité, pour atteindre un objectif donné.
Exemple : Réduire l'empreinte carbonne. Dans un scénarion apocalyptique, l'IA pourrait se dire : "Ok, si on enlève les humains, plus de problème d'empreinte carbone !"
D'un autre côté, l'impact positif de l'IA est qu'elle permet à l'humain non pas seulement d'automatiser, mais surtout de faire des "frog leaps" vers des découvertes qui auraient pu nous prendre des décennies.
Abstraction
Capacité de l'IA à généraliser un problème ou une situation d'un point de vue plus high level. En gros, penser en concepts et modèles mentaux. Si l'abstraction des modèles s'améliore, ils sont moins coûteux à utiliser et donc se démocratisent.
Agent IA
Un agent IA est une IA qui a un impact direct sur son environnement et ce en toute autonomie. Exemple : Siri & Alexa, voiture autonomes, chatbots, etc.
Reinforcement Learning (RL)
Catégorie de Machine Learning. Des agents IA ont un objectif et reçoivent des récompenses ou pénalités en fonction de leur résultat. Ils apprenent donc avec le trial & error de la politique configurée.
Self-Supervised Learning (Unsupervised Learning, SSL)
Forme de Machine Learning non supervisée. On fournit automatiquement de la donnée brute pour que l'IA crée en autonomie ses propres labels et apprennent à les identifier. L'IA fait sens de la donnée et crée ses propres patterns.
Transformeur
Modèle de Deep Learning avec plusieurs couches d'attention. Ces couches apprenent sur quelle partie de la data se focaliser pour atteindre l'objectif de la tâche.
Model Collapse
Cette technique consiste à compresser les modèles performants existants. On prend le 80/20 des jeux de donnée d'entraînement avec une synthèse de l'information. Une fois les couches de données réduites, on corrige le tir soit avec du fine-tuning, soit un réentraînement.
Distilled Models
Les "Distilled Models" sont une conséquence du Model Collapse au-dessus. Le modèle en résultant est distillé, plus compact mais aussi performant ou presque. On commence actuellement à voir des modèles suffisamment compacts pour tourner sur des smartphones. La performance de ces modèles est une question de gestion de trade-off entre précision vs gain de performance. La data synthétisée de la sorte est malgré tout un peu alarmante, car un taux d'erreur initial légèrement plus élevé pourrait entraîner des erreurs composées.
Retrieval Model
Modèle qui va chercher dans une base de données pour retrouver une info pertinente en fonction de la requête utilisateur. Il y a une pondération sur les différents résultats possibles.
Sparse Autoencoders (SAE)
Les SAE sont des représentation en réseau de neurone. Très concrètement, ils permettent d'avoir une représentation visuelle de quels composants d'un modèle sont activés lorsque le modèle est utilisé. Cela limite le syndrome "boîte noire" qu'on pouvait avoir en utilisant un modèle.
News
Ce que j'ai appris sur l'écosystème IA. Cette semaine, principalement une retro sur 2024 et l'état actuel du secteur.
- Il commence à y avoir de bonnes alternatives à OpenAI, le fossé se résorbe petit à petit. Personnellement j'ai de bons résultats avec Claude. À essayer :
- Llama
- Claude
- Gemini
- Grok
- Perplexity
- OpenAI utilise COT + RL (voir dans les concepts !) pour gérer les prompts complexes. Les capacités de problem solving sont bonnes, mais ça reste relativement cher. Faible également dans le raisonnement spatial (AlphaGeometry est prometteur dans ce domaine).
- Améliorer la curation de données pour les jeux d'entraînement pourrait être la clé pour réduire les coûts d'accès à l'IA : moins d'entraînement nécessaire, plus rapides, etc.
- De gros modèles chinois arrivent sur le marché :
- DeepSeek
- 01.AI
- Zhipu AI
- On commence à voir de bonnes vidéos générées par l'IA. Le fonctionnement général :
- L'IA s'entraîne à faire matcher texte et IA à partir d'un jeu de données
- Puis sur de gros jeux de données de vidéos basse résolution
- Et enfin du fine-tuning sur de petits jeux de données haute résolution
- La longueur des clips est améliorable mais voici quelques acteurs à suivre :
- Runway
- Pika
- Luma
- OpenAI
- Make-A-Scene (Meta) ajoute l'audio sur la table avec Movie Gen
- Beaucoup d'applications dans le domaine scientifiques, pointues et coûteuses. Mais peuvent produire des frog leaps. Par exemple, AlphaFold a reçu le prix Nobel de chimie en 2024. Le modèle est capable de prédire rapidement la structure tridimensionnelle des protéines à partir de leur séquence d'acides aminés, une avancée qui révolutionne la biochimie.
- Mémoire et retrieval toujours compliqué pour les LLMs, tout du moins sans aide externe.
- OpenAI et DeepMind sont très présentsdans la robotique, avec DeepMind qui émerge en tant que leader (bonne efficience, capacité d'apprentissage, adaptabilité). La clé (et limitation) pour la robotique est la data. Il en faut en grosse quantité pour l'imitation et l'apprentissage.
- Cherchez Human+ si vous êtes intéressés, ou voir les cas d'usage avec Apple Vision Pro qui permet notamment de contrôler une main articulée à distance.
- NVIDIA est le seul leader car dominant sur le marché des GPU (80-90% de market share). Le plus grand cluster NVIDIA appartient à Meta, qui fait de l'entrainement LLM.
- NVIDIA est aussi leader sur la partie R&D, ils itèrent rapidement et améliorent de manière conséquence le nombre de TFLOPS par GPU (trillions d'opérations en virgule flottante par seconde).
- Il y a une volonté des gros acteurs d'affaiblir la dominance de marché de NVIDIA (acheter ailleurs, booster l'industrie).
- Challengers:
- Cerebras
- Groq
- Softbank Arm
- Dans l'ensemble pour l'IA, il n'y a pas encore de path to profitability à l'horizon. Le revenu augmente mais l'IA reste chère. Les coûts (R&D, staff, etc.) sont élevés et augmentent sans cesse. Les modèles récents et souvent plus compacts sont moins chers.
- On commence à pouvoir exécuter du code avec des outils IA, et déployer des produits Tech. La barrière technique à l'entrée reste élevée pour utiliser ces outils. Il y a une polarisation entre construire des modeles ou construire des produits.
- Mistral est le champion europée de l'IA et l'unique challenger des mastodontes mondiaux.
- Quelques entreprises (Databricks et Snowflake notamment) tournent avec des modèles propriétaires mais c'est coûteux à produire.
- Les régulations dans le monde commencent à arriver. C'est d'ailleurs un frein à la vitesse de déploiement de certains modèles notamment en Europe.
- Une question éthique brûlante est présente sur le fair use de la donnée : est-ce qu'un modèle entraîné avec le travail d'un artiste est à considérer comme du plagiat ?
- Le problème moins discuté mais pourtant bien réel est celui de l'empreinte carbone IA, car faire tourner une telle quantité de calculs sur des GPU est très coûteux et polluant.
- La rétention sur les gros acteurs des outils IA à abonnement a augmenté de 20% en moyenne sur 2024 (eg : Grammarly, Otter, Anthropic, etc.)
- La reconnaissance vocale se développe bien, le speech-to-speech est probablement l'une des grosses milestones IA de 2025.
- Les UK ont lancé la Frontier AI Taskforce, qui est le premier institut pour l'IA Safety.
- Google DeepMind propose désormais deux outils pour mieux gérer les hallucinations :
- SAFE, qui est une sorte de search engine fact-checker,
- LongFact, qui dispose d'un dataset permettant pareillement d'évaluer la véracité d'un fait.
- Il y a un fort enjeu autour de la création de support d'utilisation de l'IA pour que les personnes qui ne sont pas natifs IA puissent elles-aussi utiliser cela. Cela passe par de la documentation, de la vulgarisation, des chatbots, de l'UX, etc.
- Une autre milestone à passer : l'émergence d'agents IA proactifs. Plutôt que de devoir solliciter l'IA et nous soutenir au quotidien (eg : agent IA autonomie en écoute sur une pièce, capable de fact-check ce qu'on dit, ou de mettre en exergue nos biais cognitifs).
- Dernier enjeu intéressant : utiliser l'IA dans les algorithmes non pour présenter du contenu clivant et polarisant, mais plutôt du contenu "common ground" entre les groupes opposés. Audrey Tang est une forte advocate de cette idée.
Ressources
Les principales ressources que j'ai consommé cette semaine :

